
Cost of AI: Inference
The field of AI is growing at a pace unseen and unheard of in recent history. Most enterprises have adopted AI to some extent, they are still in the early phase of AI adoption. As they start expanding their use cases, they will need to consider the total cost of operating AI.
In my previous article on the cost of AI, I focused on build, buy or customize. In this article, I will talk about inference cost. Let's dive in.
Understanding AI Inference: Why It's Essential
Inference is a fundamental aspect of artificial intelligence, bridging the gap between training and real-world application.
Inference refers to the act of using AI model to make predictions or inferences based on the input provided. For example, you could give AI a prompt like "The sky is [blank]" and the AI would use its understanding of language to infer that the appropriate word to fill the blank is likely "blue." AI inference has a wide range of applications, from chatbots and virtual assistants to content generation, translation, and even code writing.
1. Application of Learned Models: AI models, after being trained on vast datasets to understand patterns and make predictions, must apply this learning to new, unseen data. Inference is the process through which these trained models are used to make predictions or decisions based on fresh input. It's where the AI proves its value, implementing its training in practical, real-world scenarios.
2. Real-Time Decision Making: For many applications, such as autonomous vehicles or medical diagnosis systems, making quick and accurate decisions is crucial. Inference allows these AI systems to analyze new data in real time and provide outputs that guide immediate actions, like identifying obstacles on the road or recognizing malignant cells in a scan.
3. Scalability of AI Solutions: Inference enables the deployment of AI solutions at scale. For instance, a retailer using AI for personalized recommendations needs the model to infer preferences for millions of users based on their browsing history and purchase behavior. Efficient inference processes ensure that these recommendations are delivered swiftly and accurately, enhancing user experience and driving business value.
4. Cost-Effective AI Implementation: Efficient inference can significantly reduce operational costs. By optimizing how quickly and with how much computational resource predictions are made, businesses can save on infrastructure and energy costs, making AI a more viable solution across different sectors.
5. Accessibility of AI: Through cloud-based APIs and on-device processing, inference allows businesses and developers to integrate AI capabilities without the need for extensive hardware, making powerful AI tools accessible to a broader range of users and applications.
Who are major players:
While there are many companies who are providing AI services in multiple areas, I am listing down few major companies who has been either developing models to serve better output (AI21, Anthropic, Cohere, Gemini, META, Mistral, OpenAI, etc.), providing API or hosting services to serve it (Bedrock, Fireworks, Replicate, SageMaker, TogetherAI etc.) and some of the hardware providers (groq, nvidia, qualcomm, etc.)

All of these companies are playing a major role on current footprint of AI industry when it comes to model inference. While many of you familiar with popular companies/models - such as openAI, Anthropic, NVIDIA, let me highlight couple of companies on what they are up to:
1) Fireworks: a startup funded by benchmark ventures and others, raised $25 million in their series A funding. They are innovating in how they serve various open-source models by providing serverless inference. Some of their benchmarks for generating first token output during inference is comparable to major providers and in some case beating them.
2) groq: This company went on different direction than GPUs. They created their own LPU Inference Engine, with LPU standing for Language Processing Unit, is a new type of end-to-end processing unit system that provides the fast inference for LLMs. They were in the news recently when they showcased 300 tokens per second throughput for LLaMa 2-70B model and in some cases its 15x faster than few cloud providers.
Who to use?
There are many factors to consider when deciding on your AI inference approach. Some decision criteria should be:
1) Where my data and rest of the applications are?: Inference workload is heavily dependent on the data, as for each inference call, you will use the data either during the input or the output of the inference, or in some cases, both - as you integrate your applications with LLMs. If your data is in, let's say, AWS cloud and you want to use OpenAI's GPT-4 model, every time you invoke GPT-4 API calls, you are sending data out of AWS to Azure/OpenAI and there is a data transfer cost ($0.01 per GB as of this writing). So for 1TB of data, it's like $10 - not bad if your AI cost itself is in few thousand dollars.
2) what is the use case?: Do you need fast inference or it can wait few minutes to few hours? If you are doing summary of large documents for once a quarter, most likely you can wait for few hours for that summary to get generated. Thus you better off using batch inference. But if your application is providing real-time information via chatbot or similar setup, you better apply real-time inference and potentially fast but cost-efficient.
3) Context length: This is very important when it comes to selecting the model as each model has different context length and that plays a pivotal role in decision making process. Would you be OK with 128K of GPT-4 or 200K from Anthropic. Or you will really need 1M token context window from Gemini. The larger the context window, the more data you can send it to model.
4) Open-source or closed-source: This goes by the organization culture and how they want to utilize the model. With advancements in open-source models from META, Mistral, they are performing very close or par to their closed-source peers, such as Claude and GPT-4. If you decide to use open-source model, you will need to find a provider who can run your open-source model in their infrastructure: it could be any cloud provider such as AWS, Azure or new entrants like groq or fireworks.
Real-world use case:
Let's take the same use case (what we took in build vs. buy) of reviewing various financial documents and summarizing them.
Let's assume that your users are required to review various financial documents, such as public companies quarterly or annual reports? As per American Accounting Association, mean annual reports are 55,000 words (~ 75K tokens). Assuming that as a part of summary, model is giving us 20% of the text (11,000 words or ~15K tokes) let's calculate the cost of doing this summary for one company. There are 58,200 publicly listed companies in the world. If your users need to summarize all of their annual reports, what will be the cost? Do they also need to summarize quarterly reports?
There are few ways you can solve this :
1) hosting your own model with services such as Amazon SageMaker, Replicate or even with HuggingFace. For hosting your own, it comes down to the GPU pricing as each of the service providers offers GPU at varying price with added advantage of using their services for various purpose - in this case, SageMaker is feature rich service in comparison to Replicate or Hugging Face. So make your decision on using these services based on additional features you may be able to use. I am biased but SageMaker is a winner here.
2) alternatively, use API providers. One can use OpenAI via Azure, Amazon Bedrock (with multiple models within it) or new kid on the block - Groq (not the Grok of Twitter or X).
Going back to our example of doing summarization, let's do the math in terms of words and then tokens (reminder: 750 words in english ~= 1000 tokens):
total annual report words = 58,200*55,000 = 3.2 billion words = 4.3 billion tokens
total quarterly report words = 58,200*41,000 = 2.3 billion words = 3.2 billion tokens
total input (yearly + quarterly reports) = 7.5 billion tokens
total output (yearly + quarterly reports) = 1.5 billion tokens
The formula to calculate the cost for inference using API services is very simple:
Cost of inference = (no. of input token price for input token) + (no. of output token * no of output tokens

Let's see the same data in bar chart to do comparison in a visual format
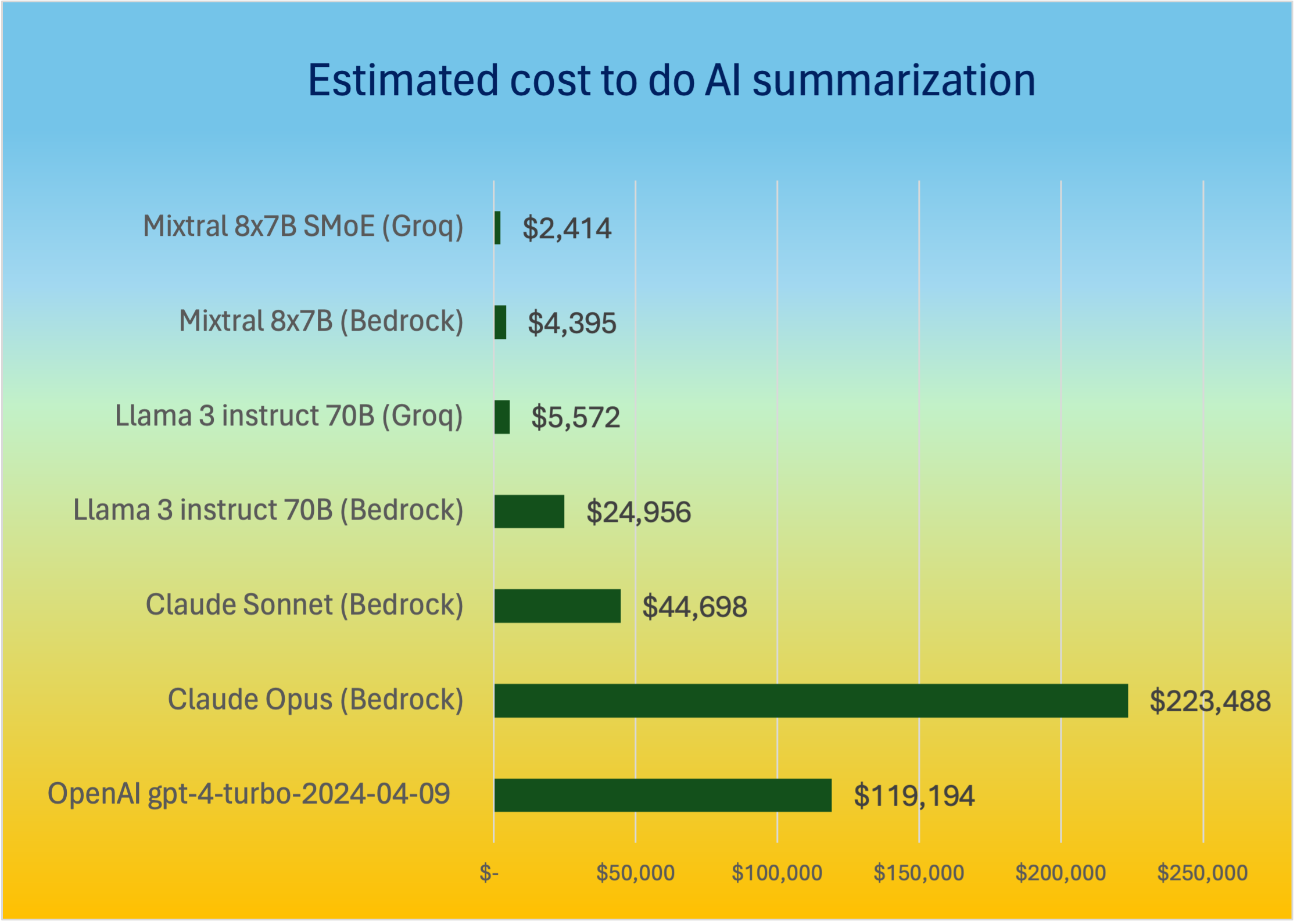
As we can see from above data, for doing our summarization using closed-source models, such as OpenAI's GPT-4 or using Anthropic's Claude Opus - two of the best model available in the world, is quite expensive in comparison to the open-source models such as Llama 3 and Mixtral. Though one thing to note that using Llama 3-70B on Amazon Bedrock for our use case is almost 4.5 times expensive compared to the new entrants like Groq. While doing the comparison for your actual use cases, do remember that by hoping over to Groq cloud for doing inference will add the latency to your overall workflow, unless your entire workflow is in the Groq cloud.
In case someone is wondering how Groq is able to provide relatively cheaper than rest of the world, the answer is - their own chipsets. Rest of the world takes what NVIDIA gives - A100, H100 and many other GPUs. Everyone timeshares the GPU and add margin on top of it. While Groq using their own chipsets, not only able to deliver the throughput but also performant on the price. Here is the chart highlighting the analysis from SemiAnalysis on how Groq compares to NVIDIA for an entire bill of material.

https://www.semianalysis.com/p/groq-inference-tokenomics-speed-but
Conclusion:
The field of AI is still evolving and we are in very early stage of AI adoption across the world. As the time goes, there will be multiple new use cases created, many ways model creators be able to serve their users and new chips will be developed to make inference faster, provide higher throughput and better results at the end of the day. If you are the one making decision around inference for your company, do consider total cost of ownership by identifying how many use cases you intend to solve, which model would work best for those use cases and what is an anticipated cost for them. You may end up in a situation where 50% of your use cases are solved by GPT-4 (great reasoning skill), 30% of them are solved by Claude's Haiku (fast and better output) and remaining 20% of them are solved using Groq because of their speed on inference (good use for agent based workflow - more on agent based workflow in upcoming newsletter). The world is hybrid - so be ready to adopt it!
What do you see in the future of AI?